AIエージェントの働きは、与えるツールの質によって大きく変わります。実際の現場では、仕様があいまいなツールや評価されていないツールを使うことで、誤った呼び出しや余計なコスト、タスク未完了といった問題が起きがちです。 Anthropic が公開した「 Writing tools for agents」では、プロトタイプの作成から評価方法、Claude を使った自動改善、そしてツール設計の基本原則までをまとめています。
本記事では、その内容をかみくだいて紹介し、業務にすぐ役立つ形で整理します。
目次
- ガイドの全体像
- ツールの定義と従来ソフトウェアの違い
- 実装と評価の進め方
- プロトタイプの構築 Claude CodeとMCPの活用
- 包括的評価の設計と運用
- 結果分析と改善
- Claudeによる自動最適化と一括リファクタ
- Interleaved Thinkingの活用と出力設計
- 設計原則(選定・名前空間・文脈返却・効率・記述)
- 応答形式とコンテキスト設計(ResponseFormat/ID設計)
- トークン効率とエラー設計
- 名前空間とツール選定の実践
- 統合ツールの設計例
- 実務チュートリアル
- よくある落とし穴と回避策
- 実例と効果の補足
- 導入チェックリスト
- まとめ
ガイドの全体像
引用: https://www.anthropic.com/engineering/writing-tools-for-agents
このガイドは、ツールを「エージェントにとって扱いやすい形」で設計し、評価と改善を繰り返すことを前提にしています。
流れはシンプルで、 まず試作(プロトタイプ)を作り、評価を設計して実行し、その結果をもとに Claude で改善を行います。あわせて、ツールの選び方や名前の付け方、返す情報の工夫、トークン効率の最適化、説明文の書き方など、設計時に気をつけるべき原則も提示されています。
評価に使う タスクは、できるだけ実際の業務に近いものを設定することが推奨 されます。また、正解はひとつではなく複数の解法があることを前提に検証を行います。
こうした考え方を取り入れることで、導入段階から「評価と改善」を標準の工程に組み込みやすくなり、短期間で品質を高められるのです。
ツールの定義と従来ソフトウェアの違い
一般的なAPIや関数は、同じ入力なら毎回同じ出力を返します。一方でエージェントは同じ条件でも異なる行動をとることがあります。そのため、ツールは「決定的なシステム」と「非決定的なエージェント」の間をつなぐ新しい種類のソフトウェアといえます。
| 観点 | 従来のAPI/関数 | エージェント用ツール | 実務ポイント |
|---|---|---|---|
| 呼び出しの性質 | 常に同一の入出力 | 使う/使わない・順序が変動 | 失敗前提で再試行しやすい設計にする |
| 設計の焦点 | 型/通信の正確さ | エルゴノミクス(誤用耐性/分かりやすさ) | 自然言語の説明・例を厚くする |
| 成功の判定 | 戻り値の一致 | タスク達成度・評価基準 | 正解が複数経路ありうる前提で評価 |
| 返却データ | 技術ID中心 | 意味の通る文脈 優先 | 名前/要約/関連メタデータを返す |
この違いを踏まえると、エラー応答や返却文脈の設計が成功率を左右することが分かります。
実装と評価の進め方
ここでは公式記事が示す”うまく回る進め方”を、使える粒度で整理します。
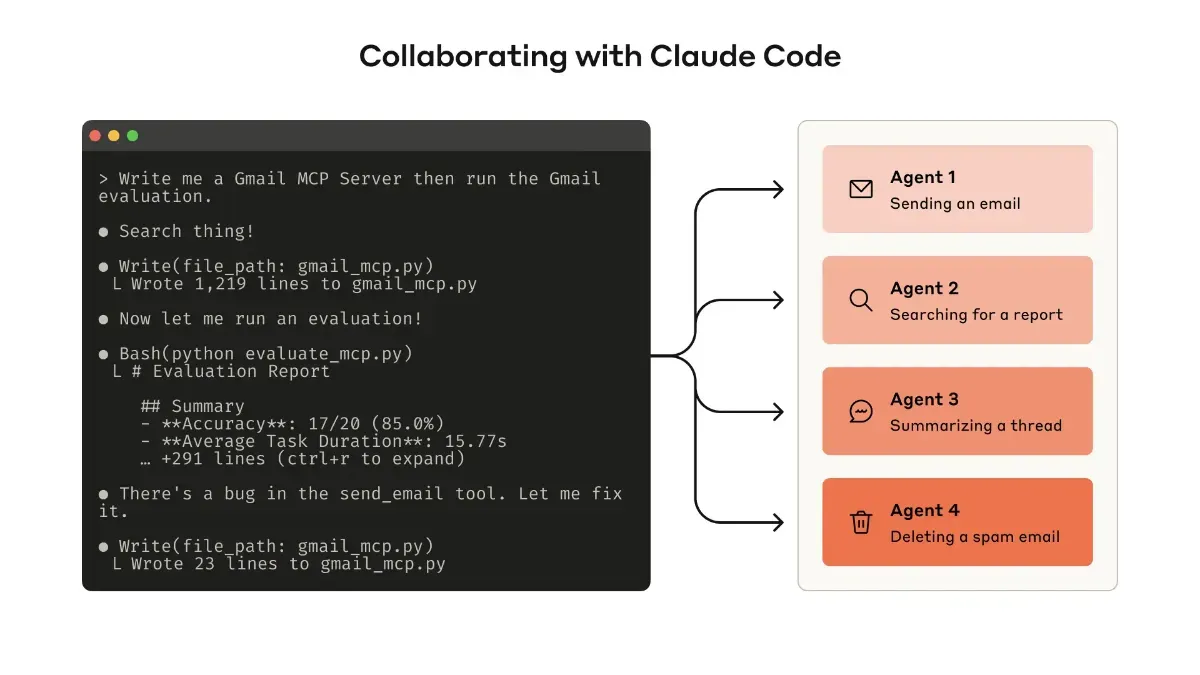
プロトタイプの構築 Claude CodeとMCPの活用
最初から完璧にしなくても構いません。Claude Code を使い、まず動くものを作って試すことが大切です。
-
必要な APIやSDKのドキュメント(
llms.txt形式など)を読み込ませると生成精度が上がります -
MCP サーバーや Desktop Extension(DXT)でツールをラップし、Claude Code や Claude Desktop から接続して試せます。
接続は claude mcp add <name> <command> を使い、Desktop の場合は「Settings > Developer」や「Settings > Extensions」から設定します。
- APIに直接ツールを渡し、プログラマブルにテストすることも可能 です。
まずは自分で試し、使いにくさを実感しながら改良していく流れが推奨されています。
包括的評価の設計と運用
プロトタイプができたら、次は評価です。
強いタスクと弱いタスク
評価タスクは現実に近い複雑なものが良いとされています。
- 強い例
来週の会議を調整し、前回の議事録を添付し、会議室を予約する。/重複課金の影響範囲を調べ、関連ログを抽出する。/解約申請への対応として理由特定・提案・リスク確認を行う。
- 弱い例
単に会議を1件登録する。/ログから1件のエントリだけを探す。
検証設計の工夫
正解判定は単なる文字列一致では不十分です。表現の違いを許容する柔軟な判定を取り入れ、複数の解法を認める設計が推奨されます。期待されるツール列を指定することもできますが、固定しすぎると過学習につながるため注意が必要です。
評価出力の設計
評価時は、回答だけでなく「理由やフィードバック」をツール呼び出しの前に出させると改善点を見つけやすくなります。Claude では Interleaved Thinking を利用することで、この流れを自然に実現できます。
このように複合的な課題を用意すると、本番運用に近い耐性を確かめやすくなります。
結果分析と改善
評価で得られるのは「答えが正しいか」だけではありません。ログを見れば、 どのツールが呼ばれなかったか、 どのツールが空振りしたか、 冗長な呼び出しが発生しているか などが分かります。
-
不要な呼び出しが多ければ、ページネーションやフィルタを設ける。
-
同じ手順が繰り返されるなら、複数の処理をまとめた「統合ツール」にする。
-
エラーが多ければ、ツールの説明やパラメータ名を改善する。
さらに、評価ログをまとめて Claude Code に与えることで、一括リファクタが可能です。命名規則や記述の整合性を短時間で整えられます。
Claudeによる自動最適化と一括リファクタ
評価で得たログを一括で活用し、Claude Code にまとめて渡してツール群を同時に見直します。
-
記述の矛盾を洗い出して整え、命名規則をそろえられます。
-
エラー応答のテンプレートを一本化し、再試行の成功率を上げられます。
-
まとめて直すため、人手だと漏れがちな”全体の整合性”を底上げできます。
-
社内事例では、人手実装よりも Claude で最適化後の方が保持アウト精度が向上 したケースが確認されています。
この工程を評価サイクルに組み込むと、短い時間で面として品質を引き上げられます。
Interleaved Thinkingの活用と出力設計
評価プロンプトの設計を少し工夫すると、改善点が見つかりやすくなります。
-
ツール呼び出しの 前 に「理由やフィードバック」を出力させるよう指示します。
-
Interleaved Thinking を使うと、 思考→ツール→思考 の流れを自然に追跡できます。
-
その結果、なぜ特定のツールを選ばなかった(あるいは選んだ)のかを具体的に分析できます。
出力の置き方を決めるだけでも、評価の解像度が一段上がります。
設計原則(選定・名前空間・文脈返却・効率・記述)
原則は多面的なので、ポイントと失敗例を対比で整理します。
| 原則 | 実践ポイント | 典型的な失敗 | 補足 |
|---|---|---|---|
| ツール選定 | 自然なタスク単位 で厳選 | API を機械的に全包し”道具箱化” | 実務の”まとまり”に合わせて統合 |
| 名前空間 | 境界が直感的 な命名 | 役割が重複し誤用が増える | prefix/suffix は 評価で決定 |
| 文脈返却 | 高信号のみ 返す | UUID 群や冗長メタで文脈浪費 | 名前/要約/軽量IDを優先 |
| 効率設計 | ページング/フィルタ/範囲/切詰 | 一発で大取得→トークン過多 | 既定方針をツール説明に明記 |
| 記述最適化 | 曖昧さ排除と例示 | user 等の曖昧パラメータ | user_id のように具体化 |
この表を見ながら、該当する改善を一つずつ適用していくと効果的です。
応答形式とコンテキスト設計(ResponseFormat/ID設計)
形式と ID の扱いは精度と可読性に直結します。
| 設計要素 | 推奨 | 理由 | 代替案/備考 |
|---|---|---|---|
| 応答形式 | JSON/Markdown/XML を評価で選択 | LLM の学習分布と整合を取る | 仕事の種類で最適が変わる |
| 粒度制御 | ResponseFormat = {DETAILED/CONCISE} | 文脈コストを可変に | さらに細分化も可能 |
| 識別子 | 自然言語+軽量ID を優先 | 誤用/幻覚を低減 | 技術IDは必要時のみ |
| 例:スレッド | CONCISE で本文のみ、 DETAILED で thread_ts 等を返す | 次のツール呼び出しを誘導 | 0 始まりIDも有効 |
先に形式と粒度の”切替レバー”を用意しておくと、後からの最適化が容易になります。
トークン効率とエラー設計
コストと成功率は、既定動作の設計で大きく変わります。
-
長文応答は既定で切り詰め、必要に応じて続きを取得する指示を返します(Claude Code では ツール応答を既定で 25,000 トークン に制限)。
-
小さく狙う検索(フィルタ/範囲指定)を促し、一発の大検索を避ける説明をツールに組み込みます。
-
Helpful error を徹底します。
例:「start_date は YYYY-MM-DD。例:2025-09-01。project_id が未指定なので再試行してください。」のように、 再試行に必要な最小情報 と 短い例 を返します。
既定動作で”無駄撃ちを避ける”設計にしておくと、運用後の最適化コストも抑えられます。
名前空間とツール選定の実践
命名は”選択ミスの減少”に直結するため、評価で決めます。
| 方式 | 例 | 強み | 注意点 |
|---|---|---|---|
| prefix 型 | asana_search, jira_search | サービス境界が明確 | リソース粒度は別工夫が必要 |
| suffix 型 | search_asana_projects | 資源種別まで分かる | 名前が長くなりやすい |
| 統合設計 | schedule_event | 連鎖タスクを一手に処理 | 説明とパラメータ設計が要点 |
LLM によって相性が異なるため、 評価スコアで方式を選定 するのが最適です。
統合ツールの設計例
現場の実タスク単位にツールを統合すると、戦略探索が短くなります。
-
schedule_event:候補探索→空き確認→作成まで一括。 -
search_logs:関連行と 周辺文脈だけ 返す。 -
get_customer_context:顧客の直近アクティビティを 要約+主要メタ で返す。
この方針は「連絡先は 全件 返さず、まず search_contacts で絞る」という比喩に通じます。
実務チュートリアル
まず既存 API/SDK の仕様や社内ナレッジを整理し、LLM 向けドキュメント(llms.txt 等)を用意します。Claude Code に読み込ませてツールのひな型を生成し、ローカル MCP サーバーまたは DXT で包みます。 claude mcp add ... で Claude Code に接続し、Claude Desktop の場合は Settings > Developer(MCP)または Settings > Extensions(DXT)から有効化します。十分に動く感触が得られたら、API 直渡しでプログラマブルな評価ループを回し、出力は 構造化結果+理由付け+フィードバック を含むようにプロンプトを調整します。 評価ログは連結して Claude Code に貼り込み、記述・命名・エラー応答を一括リファクタします。
よくある落とし穴と回避策
現場で頻出するつまずきを、症状→原因→対策で一覧化します。
| 症状 | 原因 | 回避策 |
|---|---|---|
| 似たツールを誤選択 | 名前空間が曖昧 | prefix/suffix を評価で選定し、説明を 1 行で要約 |
| 返却が長すぎる | ページング/フィルタ未設計 | 既定で CONCISE、必要時のみ DETAILED |
| 再試行が進まない | エラーが不親切 | 入力検証エラーは 短い例 付きで返す |
| 検索が外す | 記述の誘導が悪い | ”小さく探す”戦略を説明に明記、範囲/フィルタ推奨 |
| 評価が当てにならない | 砂場/単発課題に偏重 | 実データ/複合課題を増やし、保持アウトで検証 |
この表を使い、既存ツール群を短時間で棚卸しできます。
実例と効果の補足
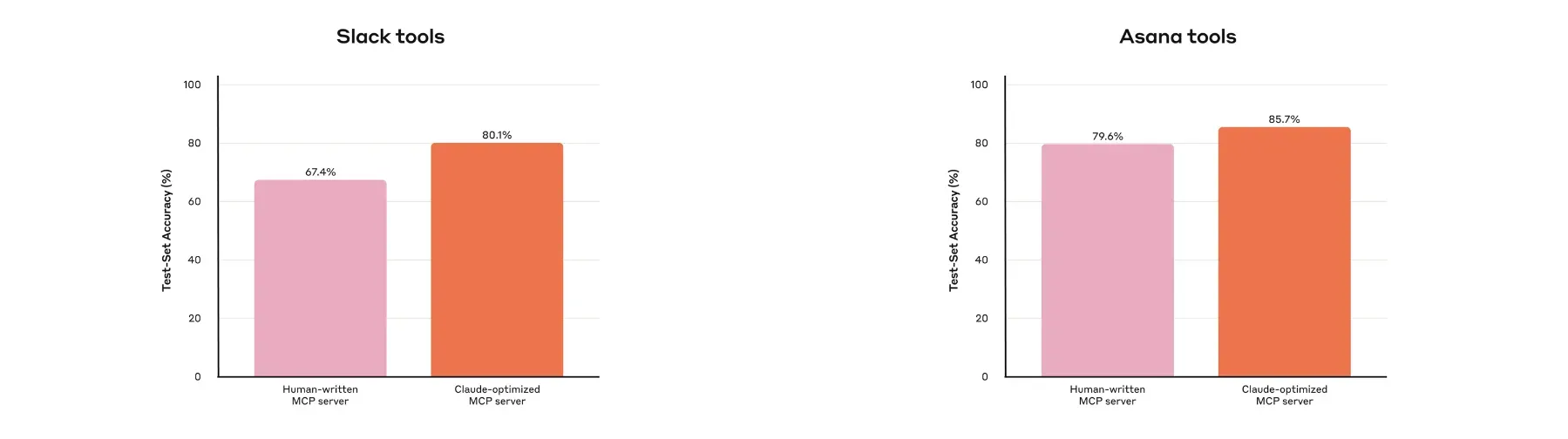
Anthropic の社内では、Slack や Asana 用の MCP ツールを Claude と共に改善した結果、人手で作ったものよりも精度が向上しました。さらに外部ベンチマーク(SWE-bench Verified)でも、ツールの説明を少し直すだけでスコアが大幅に改善した事例があります。つまり、設計と記述の工夫は性能に直結するのです。
導入チェックリスト
稼働直前の”最後の 1 マイル”で確認しておくと安定運用に近づきます。
- 評価設計
実運用の複合課題を多数・検証可能な目標を明示。
- メトリクス
成功率・ツール回数・所要時間・トークン消費・入力検証エラー。
- 効率設計
ページング/フィルタ/範囲選択/切詰を既定に。
- エラー設計
指示的で短い再試行ヒント+最小例。
- 安全注記
破壊的操作やオープンワールドアクセスの有無をツール注釈で明示。
この観点で”抜け”を塞いでおくと、初期トラブルの大半は回避できます。
まとめ
要は、 ツールを”使われる前提”で設計し、現実的な評価で弱点を可視化し、Claude と協働して短サイクルで磨き上げる ことです。まずは一つの高頻度タスクを選び、統合ツール化→MCP 接続→評価ログ出力(理由/フィードバック付き)→バッチ・リファクタという循環を回してください。応答形式・粒度・名前空間・エラー文の小さな調整でも、成功率とコストは目に見えて改善します。今日から着手できる”設計の手当て”が、エージェントの実力を最大化する近道です。