画像・動画・文書を横断する業務で、OCRのやり直し、長時間動画のレビュー、画面操作の自動化などを別ツールで繋ぐ運用は手間とコストが嵩みます。
Qwen3‑VLは、画像・動画・テキストの理解に加え、GUI上のボタンやフォームを見分けて操作できる”Visual Agent”機能、長文脈(ネイティブ256K)と動画の秒単位インデキシング、32言語OCRと構造化出力などを1つのモデルに統合した点が強みです。モデルはオープンウェイトとAPIの両方で提供され、実装・運用の選択肢が広がります。
本記事では公式情報をもとに、概要、特徴、料金、使い方、事前検討事項を整理します。
あわせてご覧ください
Qwen3 各モデルの役割と選定のポイントをわかりやすく整理
目次
- Qwen3‑VLの概要
- 主な特徴と強み
- 長文脈と長尺動画の検索と要約
- 視覚エージェントによるGUI操作の自動化
- 空間理解と時間整合の強化
- Visual Coding 画像からコードとダイアグラムを生成
- 多言語OCRと構造化出力
- Thinking系の推論力
- テキスト理解の維持
- 関連ツールと料金の整理
- 使い方と導入手順の要点
- 導入時のチェックポイント
- まとめ
Qwen3‑VLの概要

Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
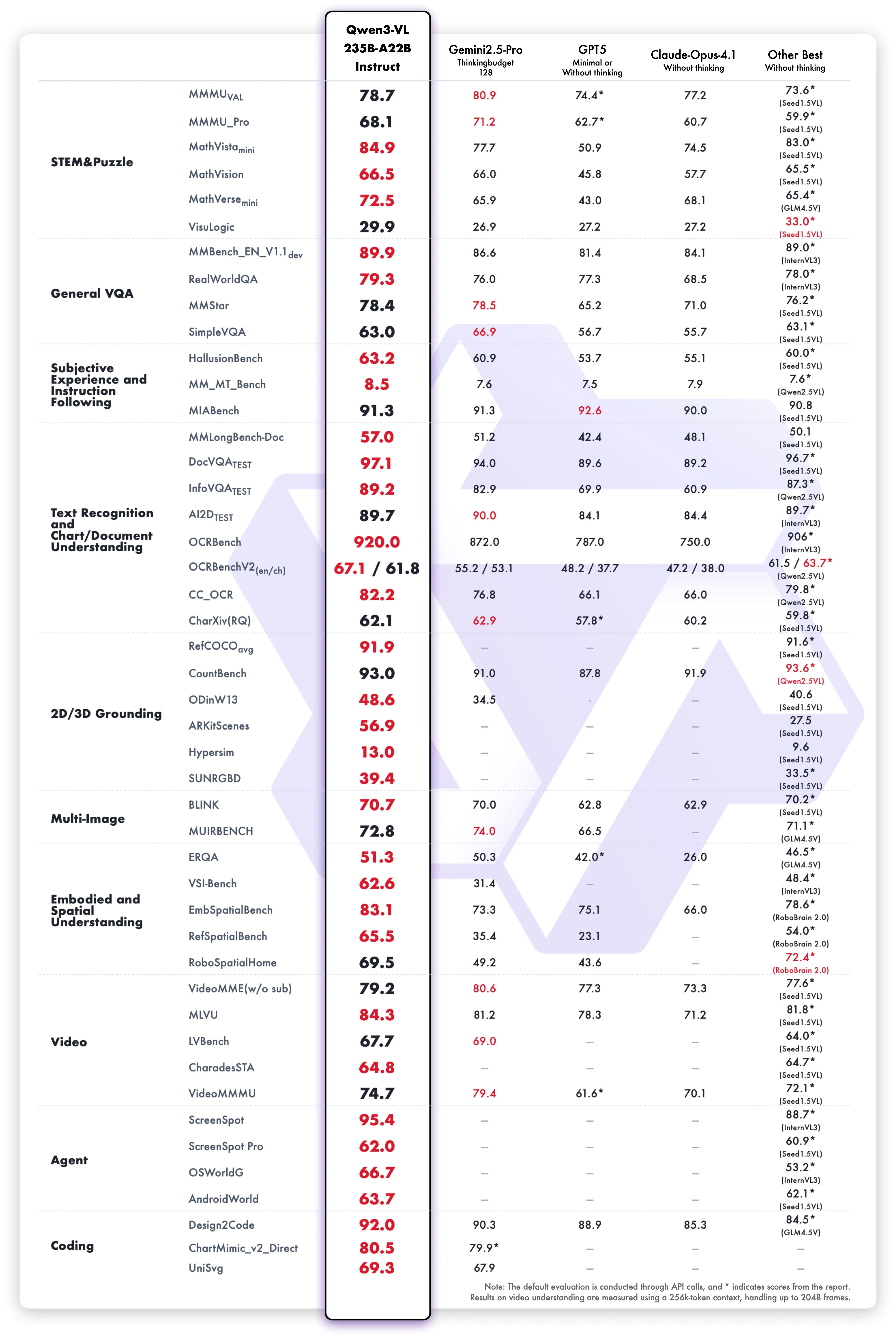
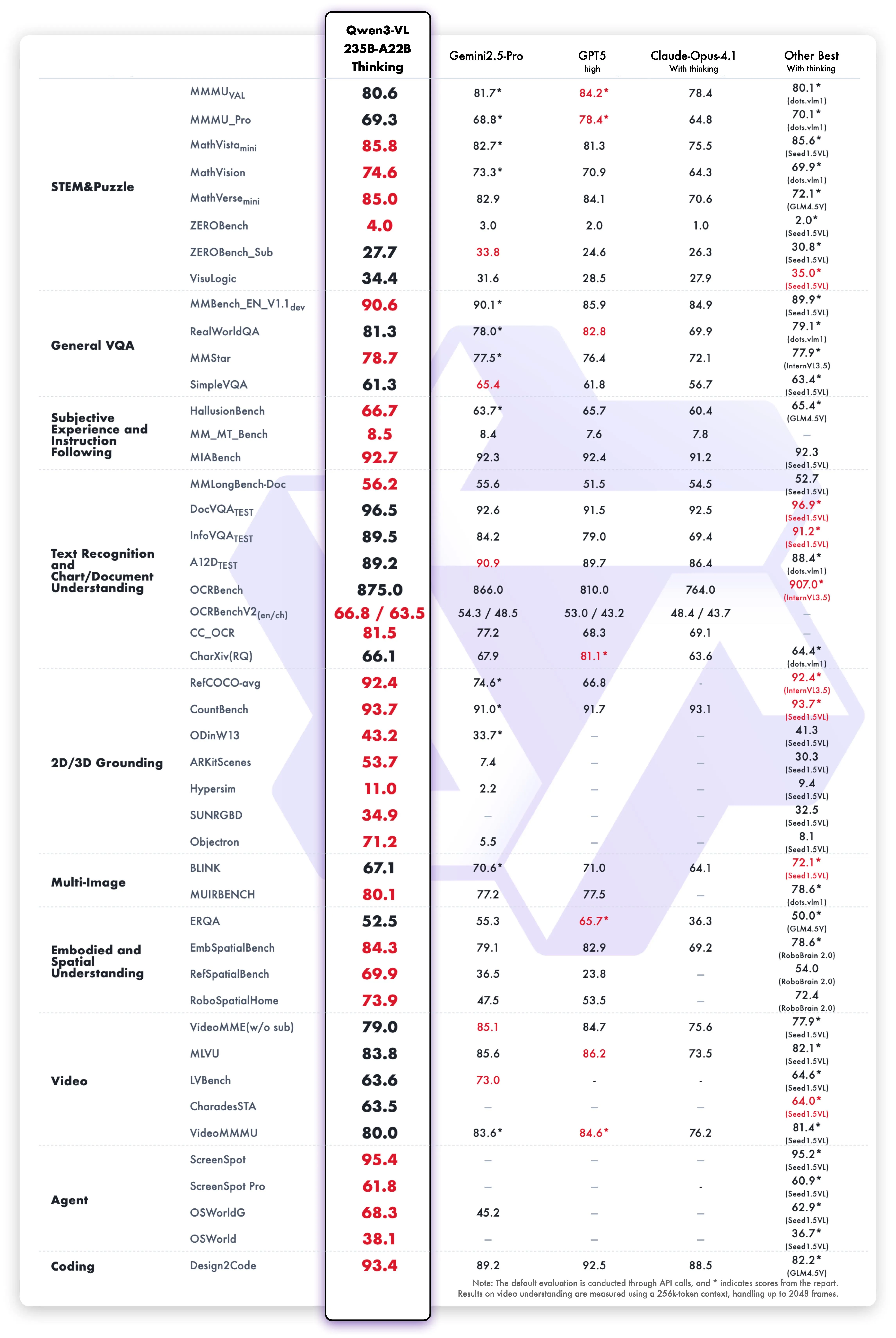
Qwen3‑VLはQwenチーム(Alibaba Cloud)が公開した視覚言語モデル群で、Dense版とMoE版、指示追従(Instruct)と思考拡張(Thinking)をラインナップしています。世代更新により、長文・長尺動画の理解、空間認識、GUI操作、Visual Coding(画像→コード生成)などが大幅に強化されました。
従来世代からの主な違いを以下の表に整理しました。
| 比較軸 | Qwen3‑VL(現行) | Qwen2.5‑VL(前世代) |
|---|---|---|
| 長文脈・動画 | ネイティブ256K(最大1M拡張)、長尺動画を秒単位で位置合わせ | 1時間超の動画理解・該当区間の特定に対応 |
| GUI操作 | 画面要素の認識・機能理解・ツール起動まで含む”Visual Agent”を明示 | タスク特化学習なしでもエージェント的挙動を示す |
| OCR・文書 | 32言語対応、暗所・ブレ・傾きへの耐性、構造化出力の強化 | 図表・レイアウト理解、JSONでの座標・属性出力 |
| 設計の更新点 | Interleaved‑MRoPE、DeepStack、Text–Timestamp Alignment 等 | 動的解像度処理など(Qwen2/VL系の改良継承) |
表の内容を前提に 続く章で実務観点の要点を具体化します。
主な特徴と強み
Qwen3‑VLは”見る・読む・探す・指示する・操作する”をまとめて扱うための設計が特徴です。
長文脈と長尺動画の検索と要約
Qwen3‑VLはネイティブ256Kトークンの文脈長を持ち、外挿で約100万トークン級まで扱える 設計です。数百ページ規模の資料や数時間の動画に対しても、出来事をテキストとタイムスタンプで結び付け、秒レベルで該当位置を指し示せます。会議録の該当発言や監査映像の該当瞬間に直行できるのが実務的な利点です。
レビューや監査での探索時間を圧縮しやすい点が実務的です。
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
視覚エージェントによるGUI操作の自動化
画面上のボタンや入力欄を”見分ける”だけでなく、その機能を理解し、必要なツール呼び出しを組み合わせてタスクを完結 できます。OS‑World等のベンチマークで上位性能を示す旨が公式に明記され、ツール使用込みで微細な知覚課題の精度が上がることも示されています。ブラウザ操作やSaaSの設定投入など、画面経由の作業自動化に直結します。
空間理解と時間整合の強化
2Dの座標表現を”絶対”から”相対”に見直し、カメラ視点の変化や遮蔽関係をより頑健に扱える ようになりました。さらに3Dグラウンディングをサポートし、 物体の位置関係を立体的に把握 できます。製造現場の手順確認やロボティクスの把持判断など、空間的文脈が効くユースケースに向きます。
Visual Coding 画像からコードとダイアグラムを生成
デザインカンプやホワイトボード写真から、Draw.ioのダイアグラム、HTML/CSS/JavaScriptの雛形を直接生成 できます。UIモックや設計書の”たたき台”を素早く起こせるため、要件定義と試作の往復コストを下げられます。
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
多言語OCRと構造化出力
対応言語は32言語。暗所・ブレ・傾きなどの劣化条件や、珍しい文字体系・専門用語に対する頑健性が強化されています。ページまたぎの段落・表・脚注などの構造を把握しやすく、JSON等の機械可読フォーマットに落とし込む前提づくりに向きます。
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
Thinking系の推論力
数学・理工系(STEM)での逐次分解、因果の手掛かり探索、根拠に基づく記述の一貫性に重点を置いた最適化 が施されています。MathVision、MMMU、MathVistaなどのベンチマークで良好な成績を示す旨が公式に記載されています。技術仕様書の検証や数理を含む設計レビューに向きます。
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
テキスト理解の維持
視覚とテキストを統合しても純テキストLLM並みの読解を目標に設計されていると明記されています。 画像や動画の”文脈”を踏まえたうえで、仕様書の要点抽出や合意文書のドラフト整形まで、言語側の品質低下を抑えやすい のが特徴です。
関連ツールと料金の整理
Qwen3‑VLはWebのQwen Chat、Alibaba Cloud Model Studio(DashScope/API、OpenAI互換)、ローカル推論(vLLM/Docker)で利用できます。
API(視覚系)の料金と上限(抜粋・2025年10月時点/人民元, 税抜想定)
| モデル | 文脈長 | 料金(0–32K入力帯, 1K tokens) |
|---|---|---|
| qwen3‑vl‑plus(思考/非思考同額) | 262,144 | 入力 ¥0.001468 / 出力 ¥0.011743 |
| qwen‑vl‑max(2.5系, 参考) | 131,072 | 入力 ¥0.005871 / 出力 ¥0.023486 |
qwen3‑vl‑plusは入力トークン数に応じて階段課金(0–32K/32–128K/128–256K)で単価が変動します。詳細はヘルプの 料金表 をご確認ください。
使い方と導入手順の要点
ここでは”まず触る/すぐ組み込む/社内で動かす”の3観点で、手順を簡潔に記します。
Qwen Chat を開き、モデル選択でQwen3‑VL系を選ぶ。画面右側のファイル投入エリアに画像や短い動画、PDFなどをドラッグ&ドロップし、問いかけを自然文で入力して送信する。応答の下に表示される提案プロンプトや追質問を活用すると、追加の抽出や要約が効率化できる。
APIではAlibaba Cloud Model Studioでワークスペースを有効化してAPIキーを取得する。既存のOpenAI互換コードにBASE_URLをDashScopeに、モデル名をqwen3-vl-235b-a22b-instructなどに置き換える。画像URLや動画メタ情報をmessagesに含めて投げると、OCRや要約、要素検出の結果をテキスト/JSONで受け取れる。
サンプルコード
from openai import OpenAI
# Set your DASHSCOPE_API_KEY hereDASHSCOPE_API_KEY = ""
client = OpenAI( api_key=DASHSCOPE_API_KEY, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)
completion = client.chat.completions.create( model="qwen3-vl-235b-a22b-Instruct", messages=[{"role": "user", "content": [ {"type": "image_url", "image_url": {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"}}, {"type": "text", "text": "What is this?"}, ]}])print(completion.model_dump_json())自社サーバーでの運用は、vLLM≥0.11とqwen-vl-utilsを導入し、公式DockerまたはSGLangでHTTP推論サーバーを起動する。
pip install acceleratepip install qwen-vl-utils==0.0.14# Install the latest version of vLLM 'vllm>=0.11.0'uv pip install -U vllmFP8チェックポイントはH100+CUDA 12+が必要で、スループット向上とメモリ削減に寄与する。
# Efficient inference with FP8 checkpoint# Requires NVIDIA H100+ and CUDA 12+vllm serve Qwen/Qwen3-VL-235B-A22B-Instruct-FP8 \ --tensor-parallel-size 8 \ --mm-encoder-tp-mode data \ --enable-expert-parallel \ --async-scheduling \ --host 0.0.0.0 \ --port 22002導入時のチェックポイント
技術要件と運用要件を最初に明文化しておくと移行コストを抑えられます。
-
モデル選定と思考モードの使い分け
-
プロンプト設計と前処理での 入力長削減
-
ログ保存、マスキング、削除フローと監査設計
-
APIとローカルの併用による冗長化、レイテンシ要件の分離
-
権利処理、安全対策、データ取り扱い、ポリシーの明確化
前記をPoC開始前にドキュメント化すると 評価から本番までの移行が滑らかになります。
まとめ
Qwen3‑VLは、長文・長尺動画・画面操作までを一体で扱う設計が核で、Visual Agent、32言語OCR、Visual Coding、空間・時系列の強化、そして拡張可能な256Kコンテキストが実務のボトルネックを直に解消します。利用はQwen Chat、OpenAI互換API、ローカル推論から選べ、料金はqwen3‑vl‑plusの階段課金を把握して見積もるのが実務的です。まずは公式Cookbooks/デモとChatで課題に近い題材を短期検証し、成果の出たタスクからAPIやローカル推論に段階的に展開してください。