In workflows spanning images, videos, and documents, operations connecting OCR retries, long video reviews, and screen automation via separate tools incur overhead and costs.
Qwen3-VL’s strength lies in integrating image/video/text understanding with “Visual Agent” functionality to identify and manipulate GUI buttons and forms, native long-context (256K) and second-level video indexing, 32-language OCR and structured output into a single model. The model is provided in both open-weight and API formats, expanding implementation and operational choices.
This article organizes overview, features, pricing, usage, and preliminary considerations based on official information.
You may also want to read
Qwen3 Model Lineup: Clear Guide to Roles and Selection Points
Table of Contents
- Qwen3-VL Overview
- Key Features and Strengths
- Long-Context and Long Video Search and Summarization
- GUI Operation Automation via Visual Agent
- Enhanced Spatial Understanding and Temporal Alignment
- Visual Coding: Generate Code and Diagrams from Images
- Multilingual OCR and Structured Output
- Thinking-Series Reasoning Power
- Maintaining Text Understanding
- Related Tools and Pricing Overview
- Usage and Implementation Summary
- Implementation Checklist
- Summary
Qwen3-VL Overview

Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
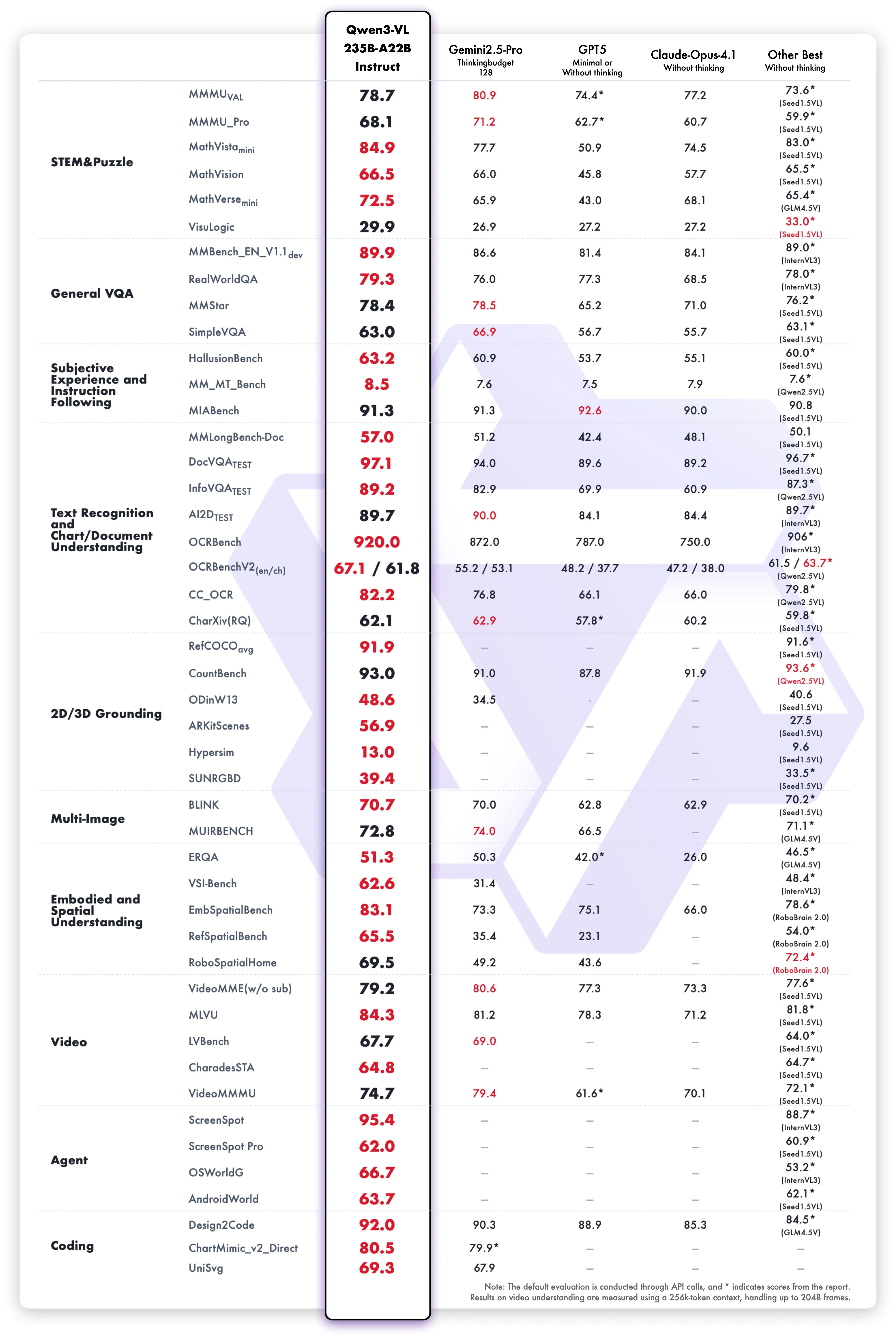
Qwen3-VL is a vision-language model family published by the Qwen team (Alibaba Cloud), offering Dense and MoE versions, instruction-following (Instruct) and reasoning-enhanced (Thinking) variants. Generational updates significantly strengthened long-context/long-video understanding, spatial perception, GUI operations, Visual Coding (image→code generation).
The following table organizes key differences from the previous generation:
| Comparison | Qwen3-VL (Current) | Qwen2.5-VL (Previous) |
|---|---|---|
| Long-context/video | Native 256K (up to 1M expansion), long video second-level alignment | 1+ hour video understanding, segment identification |
| GUI operations | Explicitly specifies “Visual Agent” including screen element recognition, function understanding, tool invocation | Agent-like behavior without task-specific training |
| OCR/documents | 32-language support, resistance to darkness/blur/tilt, enhanced structured output | Chart/layout understanding, coordinate/attribute JSON output |
| Design updates | Interleaved-MRoPE, DeepStack, Text-Timestamp Alignment, etc. | Dynamic resolution processing, etc. (inherits Qwen2/VL improvements) |
Based on this table, the following chapters concretize practical perspectives.
Key Features and Strengths
Qwen3-VL features design for comprehensively handling “seeing, reading, searching, instructing, and operating.”
Long-Context and Long Video Search and Summarization
Qwen3-VL has native 256K token context length, designed to handle up to ~1M token scale via extrapolation. Even for hundred-page documents or multi-hour videos, it links events with text and timestamps, pinpointing relevant positions at second-level precision. Practical advantage is direct access to relevant statements in meeting minutes or audit footage moments.
Practically compresses exploration time in reviews and audits.
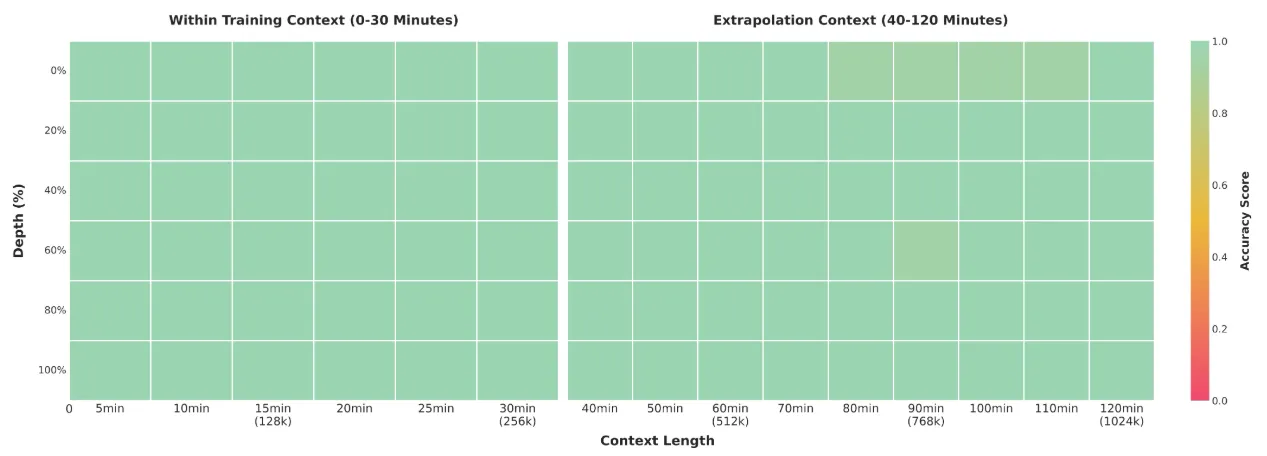
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
GUI Operation Automation via Visual Agent
Not only “distinguishes” buttons and input fields on screen but understands their functions, combining necessary tool calls to complete tasks. Official documentation confirms top performance on benchmarks like OS-World, showing improved accuracy on fine perception tasks with tool usage. Directly applicable to browser operations and SaaS configuration automation.
Enhanced Spatial Understanding and Temporal Alignment
Revised 2D coordinate representation from “absolute” to “relative,” more robustly handling camera viewpoint changes and occlusion relationships. Additionally supports 3D grounding, grasping object positional relationships three-dimensionally. Suitable for use cases emphasizing spatial context like manufacturing procedure verification and robotic grasping decisions.
Visual Coding: Generate Code and Diagrams from Images
Directly generates Draw.io diagrams and HTML/CSS/JavaScript templates from design comps or whiteboard photos. Quickly creates UI mocks and specification “drafts,” reducing requirement definition and prototyping iteration costs.
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
Multilingual OCR and Structured Output
Supports 32 languages. Enhanced robustness against degraded conditions like darkness, blur, tilt, and rare writing systems/technical terms. Better grasps structures like cross-page paragraphs, tables, and footnotes, suited for preparation to convert to machine-readable formats like JSON.
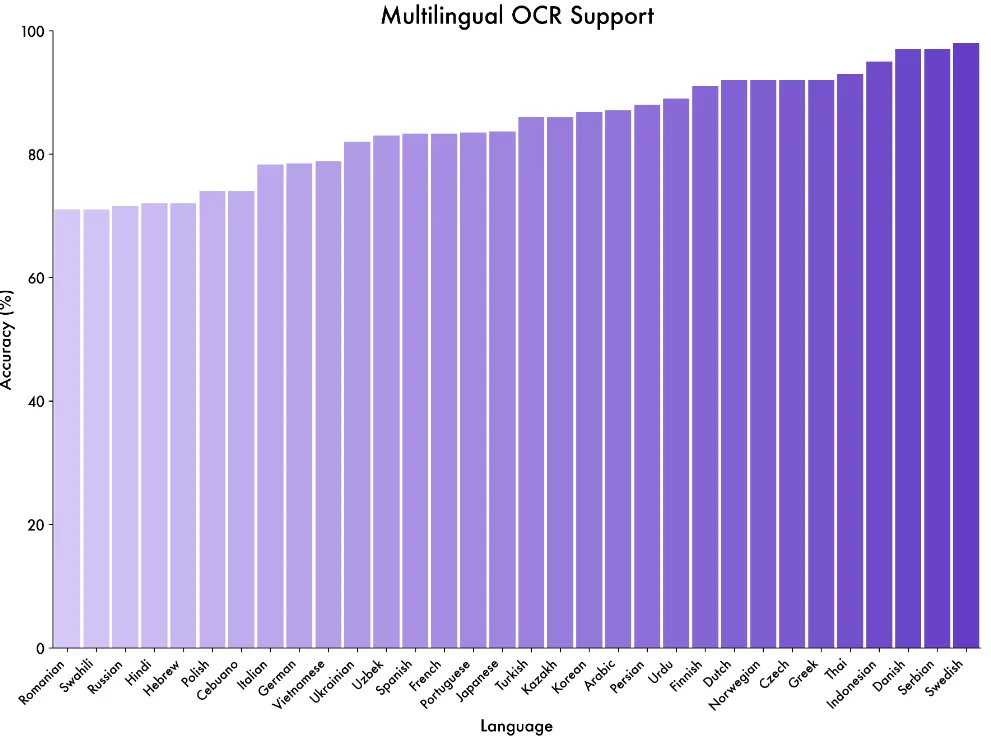
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
Thinking-Series Reasoning Power
Optimization emphasizes sequential decomposition in mathematics/STEM, searching causal clues, and evidence-based description consistency. Official documentation reports favorable performance on benchmarks like MathVision, MMMU, and MathVista. Suitable for technical specification verification and mathematical design reviews.
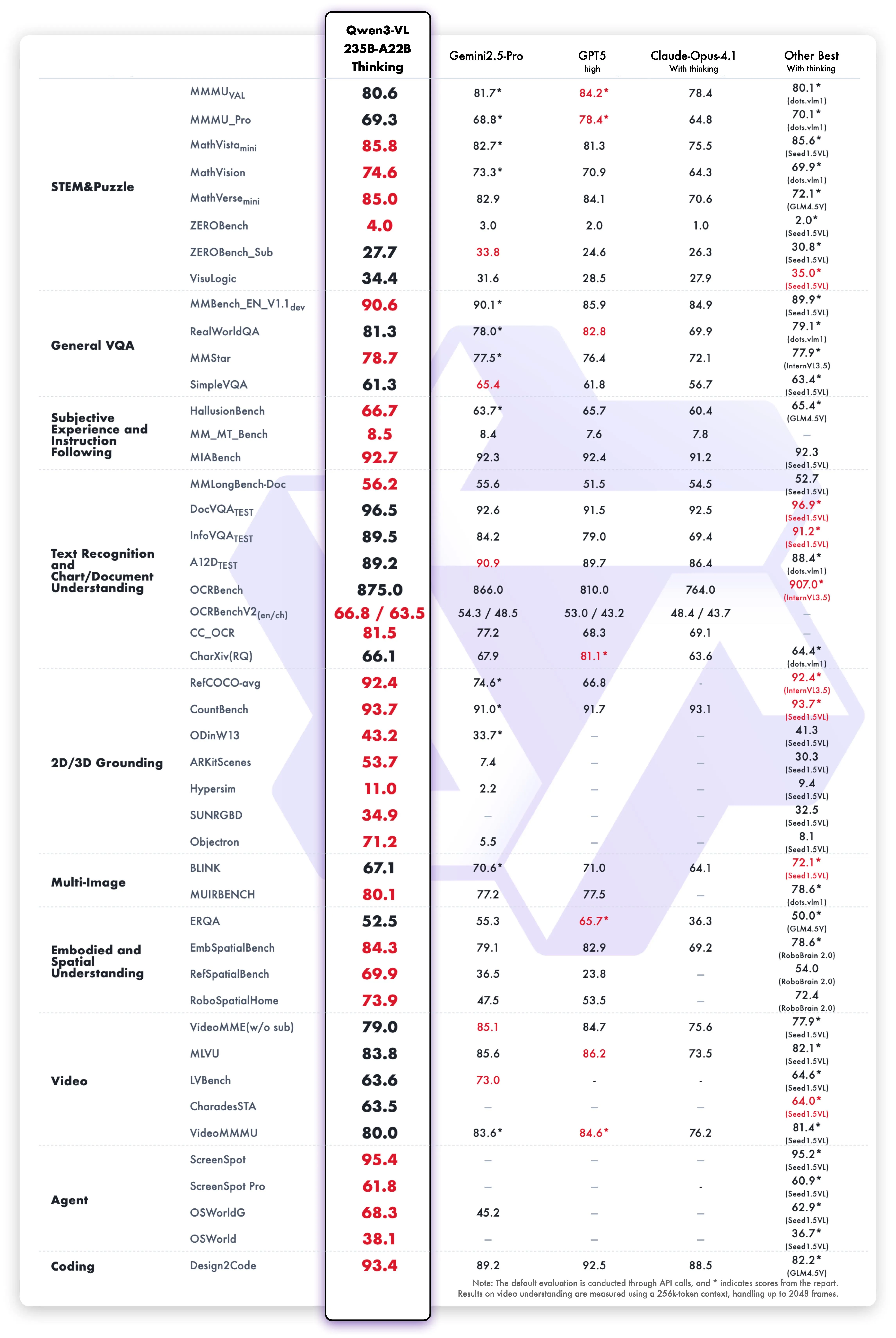
Source: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef
Maintaining Text Understanding
Explicitly designed to target pure text LLM-level comprehension despite vision-text integration. Easier to suppress language-side quality degradation up to specification extraction and consensus document draft formatting while considering image/video “context”.
Related Tools and Pricing Overview
Qwen3-VL is available via web Qwen Chat, Alibaba Cloud Model Studio (DashScope/API, OpenAI-compatible), and local inference (vLLM/Docker).
API (vision) pricing and limits (excerpt, as of Oct 2025 / CNY, tax-exclusive estimate)
| Model | Context Length | Rate (0–32K input band, 1K tokens) |
|---|---|---|
| qwen3-vl-plus (thinking/non-thinking same rate) | 262,144 | Input ¥0.001468 / Output ¥0.011743 |
| qwen-vl-max (2.5 series, reference) | 131,072 | Input ¥0.005871 / Output ¥0.023486 |
qwen3-vl-plus uses tiered pricing by input token count (0–32K / 32–128K / 128–256K). For details, check the pricing table.
Usage and Implementation Summary
Here we briefly describe procedures from three perspectives: “try first / integrate quickly / run internally.”
Open Qwen Chat, select Qwen3-VL series in model selection. Drag & drop images, short videos, PDFs into the file input area on the right, input natural language questions, and send. Utilize suggested prompts and follow-up questions displayed below responses to efficiently perform additional extraction and summarization.
For API, enable workspace in Alibaba Cloud Model Studio to obtain API key. Replace BASE_URL with DashScope and model name with qwen3-vl-235b-a22b-instruct in existing OpenAI-compatible code. Include image URLs or video metadata in messages to receive OCR, summarization, element detection results in text/JSON.
Sample Code
from openai import OpenAI
# Set your DASHSCOPE_API_KEY hereDASHSCOPE_API_KEY = ""
client = OpenAI( api_key=DASHSCOPE_API_KEY, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)
completion = client.chat.completions.create( model="qwen3-vl-235b-a22b-Instruct", messages=[{"role": "user", "content": [ {"type": "image_url", "image_url": {"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"}}, {"type": "text", "text": "What is this?"}, ]}])print(completion.model_dump_json())For self-hosted operations, install vLLM≥0.11 and qwen-vl-utils, launch HTTP inference server via official Docker or SGLang.
pip install acceleratepip install qwen-vl-utils==0.0.14# Install the latest version of vLLM 'vllm>=0.11.0'uv pip install -U vllmFP8 checkpoints require H100+ and CUDA 12+, contributing to throughput improvement and memory reduction.
# Efficient inference with FP8 checkpoint# Requires NVIDIA H100+ and CUDA 12+vllm serve Qwen/Qwen3-VL-235B-A22B-Instruct-FP8 \ --tensor-parallel-size 8 \ --mm-encoder-tp-mode data \ --enable-expert-parallel \ --async-scheduling \ --host 0.0.0.0 \ --port 22002Implementation Checklist
Explicitly documenting technical and operational requirements upfront reduces migration costs.
-
Model selection and thinking mode differentiation
-
Prompt design and preprocessing input length reduction
-
Log storage, masking, deletion flow, and audit design
-
API-local hybrid redundancy, latency requirement separation
-
Rights handling, safety measures, data handling, policy clarification
Documenting these before PoC start smooths transition from evaluation to production.
Summary
Qwen3-VL’s core design integrates long-context, long videos, and screen operations, with Visual Agent, 32-language OCR, Visual Coding, spatial/temporal enhancements, and extensible 256K context directly resolving practical bottlenecks. Usage options include Qwen Chat, OpenAI-compatible API, and local inference, with practical pricing understanding of qwen3-vl-plus tiered billing for estimates. First, conduct short-term verification on topics close to challenges using official Cookbooks/demos and Chat, then gradually deploy to API or local inference from successful tasks.